Fixing YouTube's oEmbed implementation with a custom finder class
Wagtail's Embeds feature does a great job, but sometimes the embedded content providers' endpoints don't. Here's how to fix that.
Wagtail allows you to embed external content with the wagtail.embeds module. It is implemented by default into the rich text editor, and it can be used separately by Page model fields and Stream Field blocks by using the {% embed %} tag. All of this is in the documentation.
The open oEmbed format enables content providers to specify formatted content for Wagtail to display.
- A provider makes an oEmbed API endpoint available.
- Wagtail makes a request, with the URL of some media content as a request parameter.
- The endpoint responds with (in our case) JSON containing nicely formatted HTML, among other details.
- Using the
{% embed %}tag, this content is then displayed on the page.
One question that editors might have though is why is Wagtail getting my YouTube URLs wrong?. YouTube supports adding a rel=0 parameter to the end of video URLs, to instruct the player not to show related videos when playback ends.
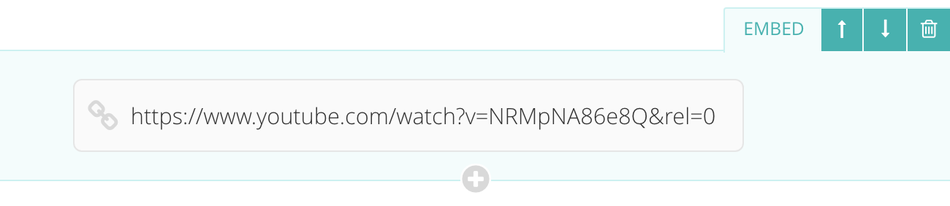
This is useful for CMS page authors, as they presumably don't want to distract readers from their page's message. However, in the formatted HTML that YouTube's oEmbed endpoint returns, the embedded player does not include the rel=0 parameter, and the related videos still show.
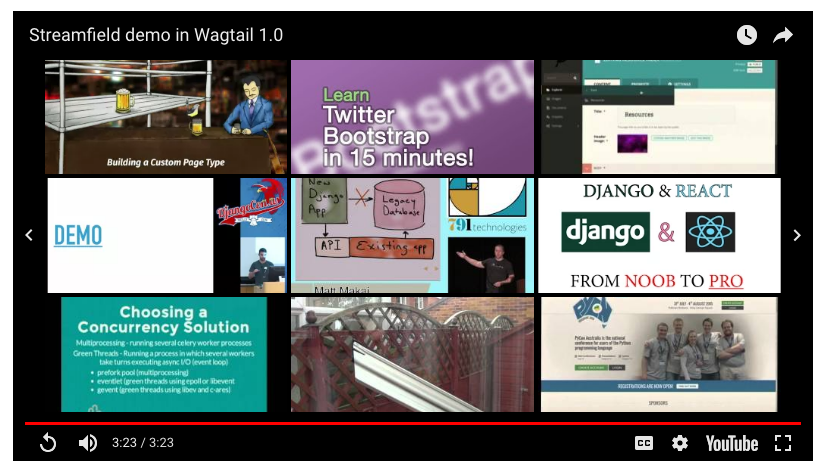
It's YouTube that is stripping this, not Wagtail, but to the CMS editor it looks very much like Wagtail is mangling the URL.
We can get around this problem by implementing a custom finder class.
from wagtail.embeds.finders.oembed import OEmbedFinder
class YouTubePreserveRelFinder(OEmbedFinder):
""" OEmbed finder which preserves the rel=0 parameter on YouTube URLs
This finder operates on the youtube provider only, and reproduces the
source URL's rel=0 parameter if present (because YouTube's OEmbed API
endpoint strips it from the formatted HTML it returns).
"""
Wagtail first sees whether there is an Embed object in the database matching the source URL; if not, it uses the relevant finder to create one. The finder returns a dictionary with a key html which in YouTube's case has a value looking like:
<iframe allow="autoplay; encrypted-media" allowfullscreen
frameborder="0" width="480" height="270"
src="https://www.youtube.com/embed/NRMpNA86e8Q?feature=oembed">
</iframe>
This is the default response from YouTube, without the rel=0 parameter. We will use beautiful soup to parse that HTML, extract and update the src attribute, and rewrite it. The formatted HTML is then stored as the .html attribute of a database Embed object, so this rewriting code will only be run once per URL.
rel = parse_qs(urlparse(url).query).get('rel')
if rel is not None:
soup = BeautifulSoup(embed['html'], 'html.parser')
iframe_url = soup.find('iframe').attrs['src']
# use urlparse to get the query from the URL
scheme, netloc, path, params, query, fragment = urlparse(iframe_url)
# and parse it to a QueryDict with parse_qs
querydict = parse_qs(query)
if querydict.get('rel') != rel:
querydict['rel'] = rel
# reencode the dict to a query string
query = urlencode(querydict, doseq=1)
# finally rebuild the URL from components, and reinsert into the HTML
iframe_url = urlunparse((scheme, netloc, path, params, query, fragment))
soup.find('iframe').attrs['src'] = iframe_url
embed['html'] = str(soup)
Some notes about this:
- We first check that the source URL has the
relparameter, and then whether the returned, formatted HTML has that same parameter and whether it's equal to the source URL's. As a site developer, you could decide instead to omit these two checks and enforce the parameter in all cases. - We used the
html.parser, because the defaulthtml5libparser attempts to 'correct' HTML fragments by wrapping in<html>tags. We don't need that behaviour.
The resulting HTML looks like:
<iframe allow="autoplay; encrypted-media" allowfullscreen=""
frameborder="0" height="270" width="480"
src="https://www.youtube.com/embed/NRMpNA86e8Q?feature=oembed&rel=0">
</iframe>
Here's the finished custom embed finder class, with some extra configuration to make sure it only operates on YouTube URLs.
from urllib.parse import parse_qs, urlencode, urlparse, urlunparse
from django.core.exceptions import ImproperlyConfigured
from bs4 import BeautifulSoup
from wagtail.embeds.finders.oembed import OEmbedFinder
from wagtail.embeds.oembed_providers import youtube
class YouTubePreserveRelFinder(OEmbedFinder):
""" OEmbed finder which preserves the rel=0 parameter on YouTube URLs
This finder operates on the youtube provider only, and reproduces the
source URL's rel=0 parameter if present (because YouTube's OEmbed API
endpoint strips it from the formatted HTML it returns).
"""
def __init__(self, providers=None, options=None):
if providers is None:
providers = [youtube]
if providers != [youtube]:
raise ImproperlyConfigured(
'The YouTubePreserveRelFinder only operates on the youtube provider'
)
super().__init__(providers=providers, options=options)
def find_embed(self, url, max_width=None):
embed = super().find_embed(url, max_width)
rel = parse_qs(urlparse(url).query).get('rel')
if rel is not None:
soup = BeautifulSoup(embed['html'], 'html.parser')
iframe_url = soup.find('iframe').attrs['src']
scheme, netloc, path, params, query, fragment = urlparse(iframe_url)
querydict = parse_qs(query)
if querydict.get('rel') != rel:
querydict['rel'] = rel
query = urlencode(querydict, doseq=1)
iframe_url = urlunparse((scheme, netloc, path, params, query, fragment))
soup.find('iframe').attrs['src'] = iframe_url
embed['html'] = str(soup)
return embed
The final task is to add this finder to the project's settings:
WAGTAILEMBEDS_FINDERS = [
{
'class': 'my_embed_finder_module.YouTubePreserveRelFinder',
},
{
'class': 'wagtail.embeds.finders.oembed',
}
]
…and observe the video ending without gaudy ads: