llms.txt - preparing Wagtail docs for AI tools
Open standards, smaller models, and better answers

One of the changes in our upcoming Wagtail 7.3 release is to publish our documentation in the llms.txt format. And that’s available right now if you’d like to try it out! Here’s how. And notes on how we got there, for people considering this for their sites.
Available now: for developers and CMS users
We’ve set up llm.txt on our developer docs and the Wagtail user guide:
- For devs: llms.txt, llms-full.txt. And per page too, see our 7.3 release in Markdown.
- For CMS users: the guide llms.txt, and guide llms-full.txt.
Hand those files over to your preferred Large Language Model, and it’ll use it to answer all sorts of questions on Wagtail projects, based on our docs. The files are available from a new "Copy" widget on the guide website:
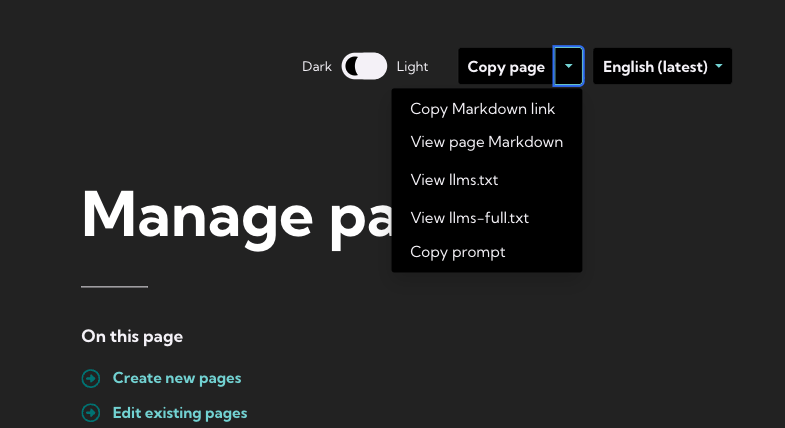
And we hope to find a similar pattern for the developer docs!
Why we’re doing this
Lots of developers and CMS users rely on AI to answer their Wagtail questions, and the format presents an opportunity to make this work better, across a wider range of AI models. Large AI providers have no problem constantly crawling websites for content, pirating books, or just running tens of web searches to answer simple questions. With our own AI-friendly format, we’re aiming for:
- Easier access to up-to-date information with open source models. No need to needlessly crawl, if all the info is in one or two optimized files!
- Equivalent performance with smaller models. The energy use and carbon footprint of AI is very roughly proportional to model size, and with authoritative information in the right format we expect more energy-efficient models to provide excellent results.
- Provider-agnostic resources. We’d rather encourage open standards and a level playing field. The Gemini Gems, Custom GPTs, Claude Skills, and Mistral Libraries can then be derived from those standards, as providers come and go.
- Authoritative answers free of copyright infringement. We’d rather AI used those official resources with permissive licenses and copyright, than learning from outdated blog posts or torrented ebooks from a decade ago.
Like our approach to AI in the CMS, we want to invest where there is opportunity to steer our ecosystem away from the pitfalls of AI.
How we did it
It’s a work in progress, but if you want to give this a go for your own project, here’s what we learned:
- Make sure the files contain equivalent information to the site’s pages. It’s not enough to provide your source format if it’s missing data that is added as part of publishing. For Sphinx docs sites, that means using a Markdown builder. For Wagtail content, you want to render your blocks’ content like you would in HTML.
- Provide multiple files. You want docs that easily fit into AI’s limitations to ingest data - so optimize for different target token counts. Fewer tokens processed means less compute, less energy use, lower environmental footprint.
- Set up an eval suite. We’re very happy with Promptfoo so far; it helps us validate that our files actually do work well with all sorts of LLMs across providers and model sizes.
Challenges to navigate
llms.txt is largely just a format and convention, and there are essential considerations to take in before deciding to go for it. If you expect your content to be heavily reused by AI, there are clear pitfalls to be aware of:
- It’s still essential to decide what information goes where. For example old news article or release notes – do we want AI to reuse those?
- What if your site traffic drops? The impact of GEO (Generative Engine Optimization) techniques isn’t well understood.
For our sites, this might mean fewer opportunities to make Wagtail users aware of our upcoming events - or to encourage them to provide feedback on our documentation. There’s not necessarily any room for tangentially-related calls to action in AI-generated content.
Analytics of llms.txt adoption
It’s also uncertain how much those files are used by different AI tools unless explicitly prompted to do so. For a small site like our guide website (50 pages, 300k human page views per year), we see:
- On the order of 300 requests for those files per day.
- Claude / Anthropic and ChatGPT / OpenAI are particularly interested about them, but so are bots from Apple, Google, Amazon, and Facebook.
Expect big request spikes, often from Anthropic’s ClaudeBot, sometimes others.
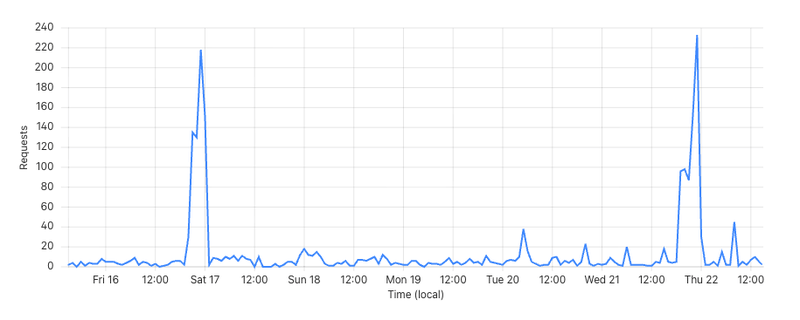
Those analytics don’t tell us how much the files actually make a difference to the experience of AI users, but they’re still a good signal that the files have relevance.
Future improvements
We are looking for feedback on those files, and will adjust accordingly. Our plans will likely include:
- Better visibility for those files across the sites.
- Opinionated prompts, to encourage different AI models to better use the content.
- More evaluation suites, to make sure small models work as well as possible.
And if all goes well, most likely an opinionated Wagtail package to more easily set this up across other sites!