Comparing open weight AI models and providers
Why and how we select open weight LLMs

It’s been a few months since we first reported on our AI usage when working on Wagtail, sharing open weight models we’re working with, as well as AI inference providers. With AI adoption levels so high in our DX with AI survey, here’s a "part two", focusing on how to select open weight models and inference providers.
Note: this is primarily focusing on agentic SWE / development tasks, with an emphasis on coding in particular. There might be other more important criteria for other kinds of AI use!
Why we prefer open weight
There’s no “silver bullet” LLM or provider that meets all our criteria. They mostly tend to fall way short compared to what we value when it comes to AI adoption. But open weight models have two key advantages that make them work out much better in practice:
- Much greater transparency. Since the model weights and model cards are provided for anyone and everyone to see, you know much more about how the models were trained and subsequently run. For example, you can easily estimate the energy use of AI inference.
- Decoupled model providers and inference infrastructure providers. This leads to market dynamics that are more favorable to inference consumers like us. Infrastructure companies are incentivized to compete with more efficient servers, and cheaper prices.
My favorite example of the above two in practice is Neuralwatt’s energy use dashboard, which shows how much energy exactly I’ve used up while coding with Kimi K2.6:
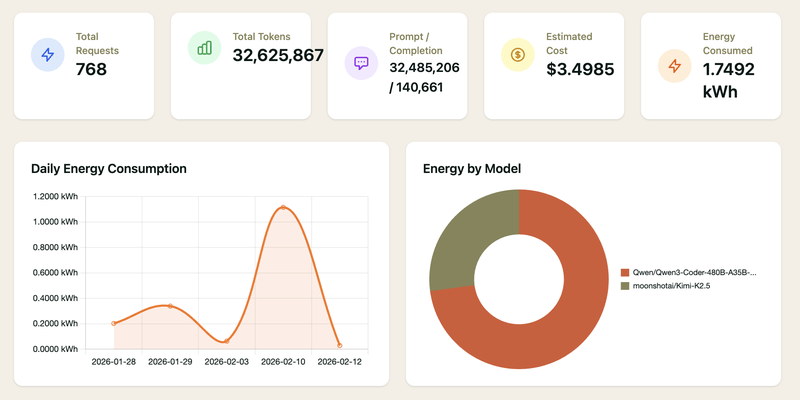
Those two advantages do result in much more work when comparing models / providers -- we have much more options, and info about them. So let’s go through our criteria!
Criteria for models
When reviewing inference options, it’s natural to be drawn to comparing models first - as their capability scores are what we all keep track of on benchmarks. Here’s what I look out for personally, as pass-fail criteria:
- Model license: is it open weight or open source. Are there specific restrictions. There are very few truly open models (Apertus, Olmo 3 from Allen Institute).
- Large context window length. A good indication of the ease of use of the model. Anything above 200k tends to work plenty well enough for any task I might want to throw at it.
- Input-output capabilities. Support for tool use, image input, JSON schema.
And the criteria that aren’t pass-fail on top, to rank models:
- Position on the pareto frontier in benchmarks. A fancy term for "capability per cost". A model is considered "pareto optimal" if it’s currently the best at a given price point.
- Energy use per request. A great proxy for the long-term cost of using the model, that isn’t influenced by any one provider’s willingness to subsidize your usage or any other aspect of their market adoption strategy.
The WebDev Arena AI leaderboard has a built-in pareto frontier visualization that you can combine with filtering to only view open weight models:
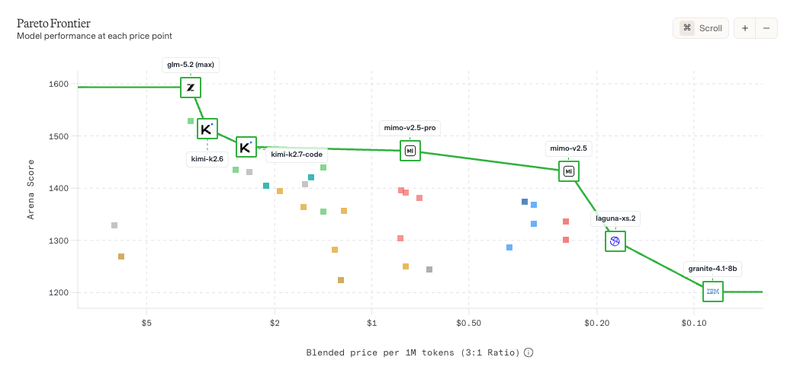
Artificial Analysis also provide excellent filterable visualizations of similar information, though it takes more effort to grasp:
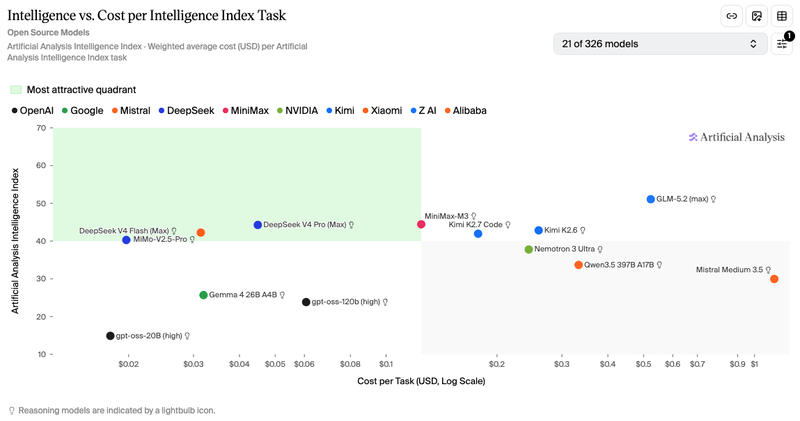
This filtering combines all of our criteria for models, except energy use. We need other datasets for that. The French government’s compar:IA models leaderboard has data for a wide range of models. Here are notable highlights when we look at both performance and energy use:
- Gemma 4 models from Google DeepMind score super high for such efficient models.
- GLM 5.2 from z.ai and Kimi from Moonshot rank higher in performance but also much higher in energy use.
- DeepSeek V4 Pro is even a step higher in energy use, but without necessarily being more performant (benchmark-dependent).
Abstract model performance and efficiency numbers are great, but when it comes to coding usage you’ll also want to see how models actually run with providers. So let’s look at that next!
Criteria for providers
There are a lot of options here too, and the ecosystem is moving fast as more and more AI users want more control and agency over how and where their usage is served. Here are the key criteria we consider, pass-fail:
- Sovereignty. Broadly-speaking, knowing which states and companies have control over the provider. For example, when looking at privacy / data protection, you want to know where the data is stored and processed but also by which entities and within what legal frameworks they operate.
- Model breadth. Having 3+ model families that are (roughly) around the pareto frontier in their recent iterations.
- Model availability lifecycle. As new models and model families get released all the time, it’s really important to know how well the provider can handle this. The server requirements of flagship AI models are enormous, so providers have to decide carefully which models to introduce in their service and also when to retire previous models.
And requirements that allow us to better rank models afterwards:
- Environmental sustainability. We want to know how much energy the LLM inference takes, and also overall data center efficiency, and the carbon footprint of the electricity source (local grid or otherwise).
- Cache hit rates. This is crucial to the cost of agentic work, and lots of providers aren’t doing too well on this. Some don’t even provide separate pricing for cache access, which is a red flag.
We chose Scaleway’s Generative APIs service back in 2025 to support our AI adoption while meeting our AI guiding principles, but these days we’re back at looking at a lot of alternatives. Here are the most promising options for us:
- Scaleway. They fare excellently on model lifecycle (clearest policy) and sovereignty (EU company, EU data centers) but their cache support and model breadth is too limiting.
- Neuralwatt. Their unique energy transparency and pricing model is unmatched.
- TensorX. EU company working with US (Ireland) and EU (Finland) data center providers. Great model breadth but the lifecycle is unclear.
- Argyll Data. A new UK-based provider with plans to build their own data center using renewable energy in Scotland.
Where next
We hope this information helps with transparency, and encourages more people to give a go to open weight models and providers! There’s a lot to navigate but it really doesn’t take that much time to get set up with a provider running a flagship Chinese model, at Opus-comparable performance but 10x cheaper. Or pick Gemma 4 for an even lower footprint.
For Wagtail, we’d love to demonstrate how to compare the output of multiple models on given agentic tasks in the future. Perhaps a Wagtail upgrade skill benchmark? That’d make for a great Wagtail Space 2026 talk proposal 🤫